Lessons learned while refactoring javascript
Lessons learned while refactoring javascript
I’ve just spent the last week refactoring a large chunk of untested code. This came about from having to fix a bug there, but realizing there was absolutely no way that I would be able to write a regression test to prove the bug was tested and fixed.
So I set off on a journey to clean up the code, and to give myself and my team the assurance that the code was tested.
Understanding the code
Confronting some unknown code can be daunting at first. Sometimes the code being investigating was done as a quick fix. Maybe the author didn’t even understand their fix, but it worked so they left it to stay for the ages. I’ve encountered bug fixes that feel as if they were accidental. If a bug fix will cause code changes, make sure to fully understand how the changes impact the codebase.
Common bad code
While refactoring code, I’ve encountered some common patterns that, with some reasoning can be fixed fairly easily.
God-objects are huge chunks of code that do too much. If encountering such code, try to organize it into smaller relatable chunks of code that can be separated and tested appropriately. This will make it easier to make changes down the road.
Overly diluted code is code that is prematurely abstracted, causing it harder to follow the flow of the code. When straightforward code is moved out into its own private function, it costs future developers more time to dig one more layer to truly understand whats inside, when quite frankly that “abstracted” code was simple enough to have remained.
Here’s an example:
This is a dumbed down example, but I’ve seen abstractions similar to this, where the developer thought they were reducing duplication, but in fact that are creating more diluted, harder to reason about code.
Use factories to create new objects. I hope most people have figured this one out, but if the keyword “new” is sprinkled throughout the code, then most likely factory methods are not being used. Here are two great resources for getting started with factories:
- funfunfunction — Factory functions in javascript
- Addy Osmani — Essential js design patterns #factorypatternjavascript
Make dependencies more obvious. This, is a non-issue for most developers using a module loader. Requirejs and Commonjs are both well suited for declaring dependencies, making them obvious. That being said it’s still possible to encounter code with unclear dependencies.
Below are examples of good and bad declarations of dependencies:
Use a linter to catch un-used dependencies (and many other code flaws), which in turn keeps the code much cleaner. By declaring dependencies, the linter will catch the unused dependencies. If the code looks like the “Bad” example then it most likely won’t catch unused dependencies.
Eslint also can be configured to enforce a styleguide for the code. I think this is great for a codebases readability (may I suggest using airbnb’s eslint template).
Refactor using a test first approach
We’ve identified the bug, and now have a better understanding of the code. With this knowledge we can approach refactoring that code, but this time with unit tests that verify our code acts as we expect.
When refactoring, I pretend as if I’m writing the code for the first time, except that the existing code acts as the specifications.
This approach is particularly useful because it helps take a large refactoring, and breaks it into a smaller, more manageable refactoring.
When writing the new code, first write the test that explains what the code should do (remember, the specifications are the existing code, but ultimately end up being your interpretation). Now it’s possible to “move” that code from the untested god-object and into the much smaller, much more clearly intentioned classes which even contain a test!
I get that this technique might be hard to visualize, and of course every situation and codebase is different; but hopefully this will lead the code in the right direction.
Keep the markup simple
It’s pretty easy to find oneself fixing a bug within the html by throwing some logical javascript to see if the bug is fixed. Sure, that’s fine to verifying the fix, but please don’t leave it like that! It’s incredibly difficult to test that logic, and may cause issues for future developers trying to find the code handling that logic.
By moving that logic back into the javascript, and binding the markup to that method; the code can now be easily tested to ensure that it’s working as intended.
Reviewing the metrics
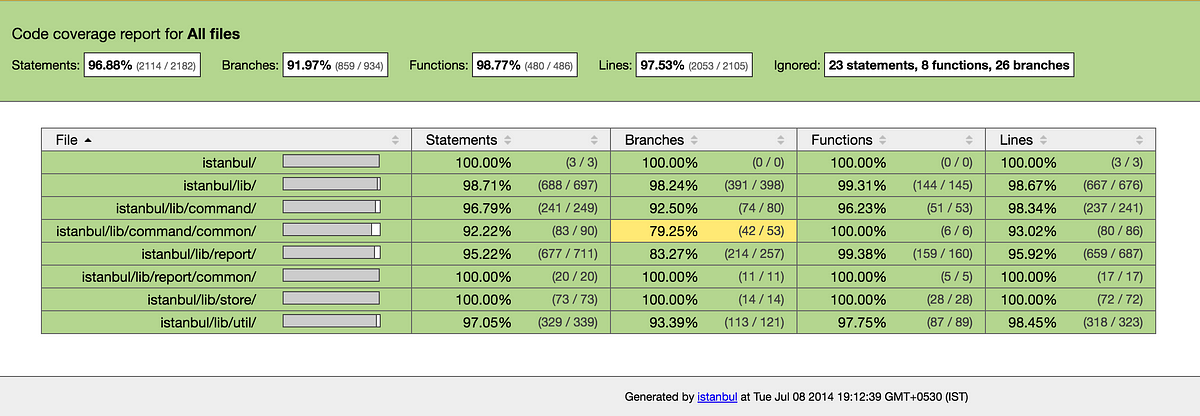
Code coverage metrics won’t solve any problems alone, but it will give insights into the codebase. These metrics will help provide the team with some level of trust regarding the codebase.
Code metrics have helped me understand my own impacts when I refactored this god-object; I managed to raise code coverage which in turn instilled me with a much stronger sense of trust in the code I am responsible for.
Setting up code coverage on an existing codebase will help expose areas of the code that will be risky to update, add functionality, and change down the road. If future features are planned for that section of the code; it might be worth first spending some time to refactor and test. Given a comfortable level of coverage, one will feel more comfortable making changes for the new functionality without breaking existing functionality.
Be aware though that one can over test the code. If one finds themselves making changes and breaking a handful of unit tests, it’s a sign that there is test overlap which reveals that some more basic unit tests can be removed.
Martin Fowler has a great post regarding code coverage regarding the subject.
karmajs is an easy to configure and run testing tool that provides a coverage plugin. For those not using something already, I would strongly recommend karmajs.
Conclusion
Refactoring javascript is hard. But once it’s done, you’ll have more confidence in the code and feel better prepared for changes to come down the road. I personally feel a sense of accomplishment after a round against the code. I’ve conquered the code, and now feel prepared for any changes that I’ll encounter down the road!
here’s a link to get inspired to write unit tests!
If you have suggestions on how to refactor, or you’d like to argue over something I wrote, leave a comment below!
By Lucas Paulger on .
Exported from Medium on October 27, 2019.